
Monitoring d’un site web assurance : outils, alertes, DORA et plan de reprise
21 / 02 / 2025
En bref
Le monitoring d’un site web assurance désigne l’ensemble des systèmes de surveillance qui détectent, en continu et en temps réel, toute anomalie affectant la disponibilité, les performances ou la sécurité d’un site, d’un parcours de souscription ou d’un espace client. Il couvre six dimensions : uptime, monitoring synthétique des parcours critiques, Real User Monitoring (RUM), surveillance des APIs partenaires, sécurité/certificats SSL, et infrastructure serveur.
Ce qui distingue l’assurance d’un site e-commerce classique : les interruptions touchent des parcours à fort enjeu juridique et financier (souscription, déclaration de sinistre, renouvellement), des données personnelles de santé, et des workflows connectés à des partenaires SI — tarificateurs, gestionnaires de contrats, prestataires de signature électronique. Depuis janvier 2025, le règlement DORA impose aux assureurs et mutuelles de documenter, notifier et analyser tout incident significatif affectant leurs services numériques.
Les outils les plus utilisés dans le secteur : Datadog et New Relic pour les grands groupes (observabilité complète), Pingdom et UptimeRobot pour la surveillance uptime, Grafana + Prometheus pour les équipes qui maîtrisent les stacks open source. Budget : 50 à 500 €/mois selon la couverture et le nombre de points de contrôle.
Pour un assureur, une indisponibilité de site n’est pas qu’un problème technique. C’est un prospect perdu sur un formulaire de devis, un adhérent qui ne peut pas déclarer son sinistre le soir d’un dégât des eaux, un courtier qui ne peut pas accéder à l’extranet réseau en pleine période de renouvellement. Et depuis DORA, c’est potentiellement un incident à notifier à l’ACPR dans les 24 heures si les seuils de criticité sont atteints.
Ce guide s’adresse aux directeurs digital, responsables infrastructure et DSI des compagnies d’assurance, mutuelles et institutions de prévoyance qui veulent structurer leur dispositif de monitoring — ou évaluer si celui qu’ils ont en place est à la hauteur des enjeux.
Ce qu’il faut surveiller spécifiquement sur un site assurance
Un site d’assureur n’est pas un site vitrine lambda. Il combine des composantes hétérogènes — site public, parcours de souscription, espace client, extranets courtiers, APIs avec des SI de gestion — dont chacune a son propre niveau de criticité et ses propres points de défaillance. Le monitoring ne peut pas se limiter à vérifier que la page d’accueil répond.
| Critique | Critique | Élevé |
| Parcours devis-souscription Chaque étape du tunnel doit être surveillée individuellement : affichage du formulaire, calcul tarifaire, étape de paiement, génération et signature des documents, confirmation d’adhésion. → Un tarificateur en timeout à l’étape 3 bloque toutes les souscriptions en cours sans que personne ne le détecte avant les appels entrants. | Espace client / extranet adhérent Authentification SSO, affichage des contrats et attestations, télétransmission, téléchargement des documents, messagerie sécurisée. Une panne silencieuse sur l’un de ces modules génère des appels entrants massifs. → Surveiller les codes HTTP retournés, pas seulement la disponibilité de la page de connexion | API partenaires et SI métier Tarificateurs, gestionnaires de contrats (Actilog, Noveane…), prestataires de signature électronique, services de paiement. Un timeout d’API partenaire peut bloquer le parcours sans que votre infrastructure soit en cause. → Surveiller les temps de réponse API avec seuils d’alerte (ex. > 800 ms = warning, > 2 s = critique). |
| Élevé | Standard | Infrastructure |
| Certificats SSL / sécurité Un certificat SSL expiré génère un avertissement de sécurité dans les navigateurs qui fait fuir instantanément les visiteurs. Les certificats Let’s Encrypt (90 jours) et les certificats wildcard doivent être monitorés avec alerte à J-30 minimum. → Particulièrement critique en période de renouvellement annuel des complémentaires santé collectives (novembre-décembre). | Performances et Core Web Vitals LCP, CLS, INP (successeur du FID) impactent à la fois l’expérience utilisateur et le référencement. Une dégradation des performances suite à une mise en production doit être détectée avant que Google la pénalise. → Configurer des alertes sur les percentiles p95 et p99 du temps de chargement, pas seulement la moyenne. | Serveurs et base de données CPU, mémoire, espace disque, connexions actives, temps de réponse des requêtes SQL les plus lourdes. Les pics de charge lors des campagnes email ou des renouvellements peuvent saturer les ressources. → Les assureurs qui font des envois d’emailing massifs à leur base adhérents génèrent des pics de connexions simultanées à surveiller spécifiquement. |
L’erreur la plus courante : surveiller uniquement la page d’accueil avec un ping HTTP toutes les 5 minutes et considérer que le monitoring est « en place ». Un site peut répondre 200 OK sur sa home page tout en ayant son formulaire de devis en erreur 500 depuis des heures, ou son espace client en boucle de redirection infinie pour les utilisateurs mobile. Aurélie Duborper – Directrice Technique Eficiens
Les six types de monitoring et leurs rôles respectifs
Le monitoring d’un site assurance ne se réduit pas à une seule technique intégrée à la TMA / maintenance . Six approches complémentaires forment un dispositif complet.
1. Monitoring uptime (surveillance de disponibilité)
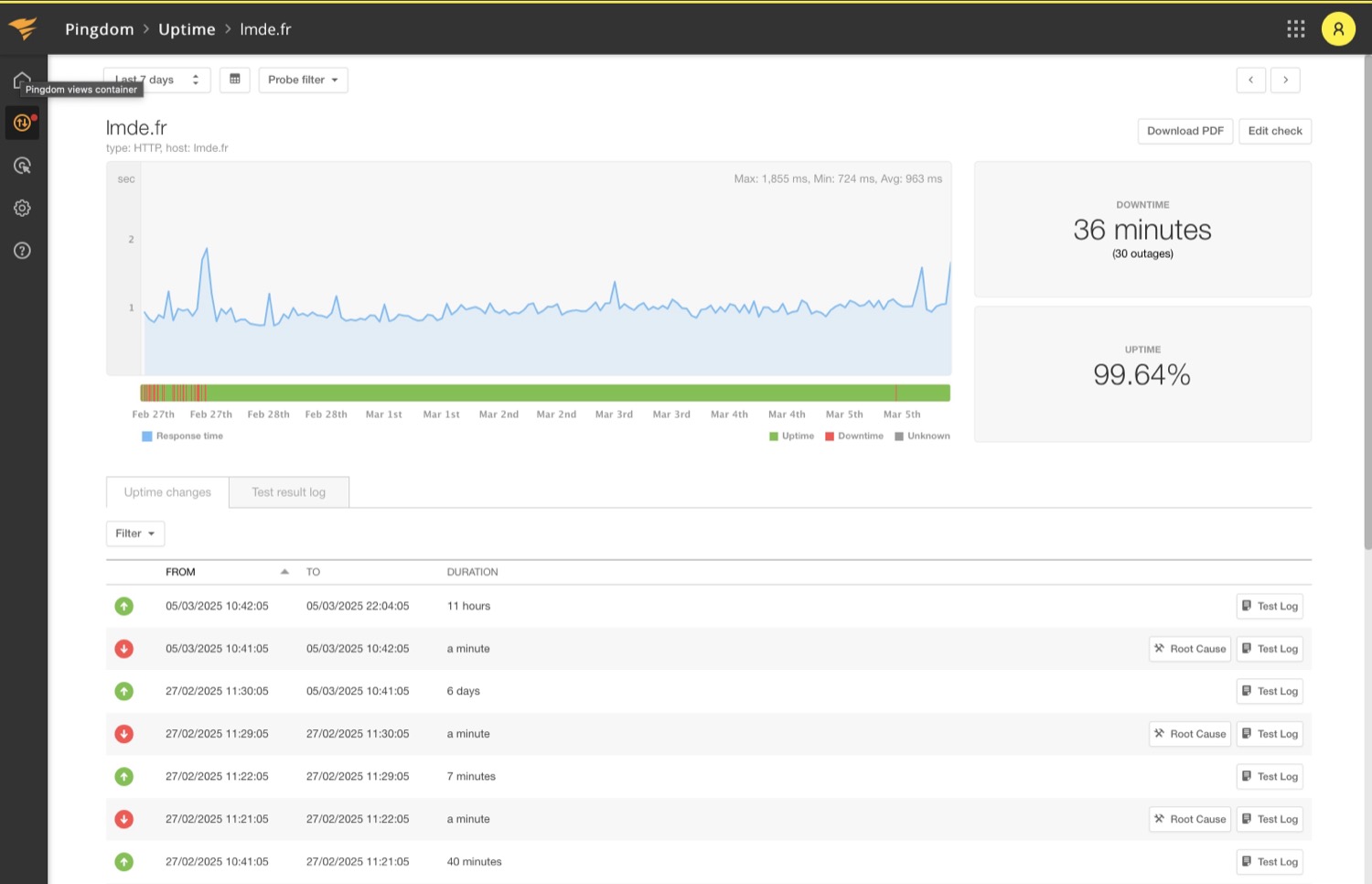
Vérifie à intervalles réguliers (toutes les 1 à 5 minutes) qu’une URL donnée répond avec le bon code HTTP. C’est la base — indispensable mais insuffisante seule. Permet de calculer le taux de disponibilité mensuel et annuel, et de documenter les incidents pour le registre DORA.
2. Monitoring synthétique (simulation de parcours)
Exécute des scripts automatisés qui simulent le comportement d’un utilisateur réel : remplir un formulaire de devis, se connecter à l’espace client, télécharger une attestation. Détecte les régressions fonctionnelles que l’uptime seul ne voit pas. C’est le type de monitoring le plus critique pour les assureurs, car les parcours de souscription comportent de nombreuses étapes interdépendantes.
3. Real User Monitoring (RUM)
Collecte les données de performance réelles des visiteurs : temps de chargement par page, par type d’appareil, par zone géographique, par navigateur. Contrairement au monitoring synthétique, il mesure l’expérience effective — y compris les cas extrêmes (connexions lentes, vieux appareils). Indispensable pour identifier les segments d’utilisateurs qui subissent une dégradation non visible en test synthétique.
4. Monitoring d’infrastructure
Surveille les ressources des serveurs (CPU, RAM, disque, réseau) et des bases de données (requêtes lentes, deadlocks, taux de cache). Permet d’anticiper les saturations avant qu’elles causent une indisponibilité.
5. Monitoring de sécurité
Surveillance des certificats SSL (expiration, validité de la chaîne de certification), détection d’anomalies de trafic (tentatives de force brute sur l’espace client, pics suspects de requêtes POST sur les formulaires), et intégrité des fichiers critiques. Particulièrement important pour les sites WordPress où des plugins mal maintenus peuvent être compromis sans déclencher d’alerte uptime.
6. Monitoring des APIs tierces
Mesure les temps de réponse et les taux d’erreur des APIs partenaires consommées par votre parcours : tarificateur externe, service de vérification d’identité (KYC), prestataire de signature électronique, système de paiement en ligne. Un partenaire qui dégrade ses performances impacte votre taux de conversion, même si votre infrastructure est parfaite.
Les seuils de disponibilité (SLA) : ce qu’ils signifient vraiment
Les SLA de disponibilité s’expriment en pourcentage annuel. Voici ce que ces chiffres représentent concrètement en temps d’interruption autorisé — et ce qu’ils impliquent pour un assureur.
99,99%
Quatre neufs
≤ 52 minutes / an
Gold standard
99,95 %
Très haute dispo.
≤ 4,4 heures / an
Recommandé espace client
99,9 %
Haute disponibilité
≤ 8,7 heures / an
Minimum site public
99,5 %
Standard
≤ 43,8 heures / an
Insuffisant en assurance
Pour calibrer votre SLA cible, posez-vous deux questions : quel est le chiffre d’affaires généré par votre site en ligne par heure d’ouverture ? Et quelles sont vos obligations contractuelles vis-à-vis de vos assurés en termes d’accès aux documents et aux services ? Un espace client permettant la télétransmission et le téléchargement d’attestations doit viser le 99,95 % minimum — son indisponibilité peut constituer un manquement à l’obligation de service.
87 %
Des incidents de performance sur les sites d’assurance surviennent en dehors des heures ouvrées, quand aucune équipe n’est disponible pour les détecter manuellement. Un système d’alertes automatisées avec escalade nocturne est non négociable. (Source : données de monitoring Eficiens / hébergements clients 2024)
Comparatif des 8 principaux outils de monitoring — angle assurance
Ce tableau évalue les solutions les plus pertinentes pour un site assurance selon les critères opérationnels qui comptent : monitoring synthétique des parcours, surveillance des APIs, conformité DORA, facilité d’intégration et coût.
| Outil | Positionnement | Uptime | Synthétique parcours | RUM | APIs / infra | Alertes avancées | Prix / mois |
|---|---|---|---|---|---|---|---|
| DatadogObservabilité complète, leader enterprise | Grand groupe | ✔ Multi-localisations | ✔ Browser + API steps | ✔Natif | ✔Complet | ✔ PagerDuty, Slack, webhook | 200 – 2 000 €+ |
| New RelicAPM + monitoring full-stack | ETI / Grand groupe | ✔Synthetics | ✔ Scripted browsers | ✔Natif | ✔ APM intégré | ✔ Alerting avancé | 100 – 1 500 €+ |
| PingdomRéférence uptime + RUM, simple à déployer | ETI | ✔ 100+ localisations | ✔ Transaction monitoring | ✔Real User | ~ Limité | ✔ Email, SMS, webhook | 50 – 250 € |
| UptimeRobotUptime basique, très accessible | PME / ETI | ✔ Toutes les 1 min | ✗ Non | ✗ Non | ✗ Non | ~ Email, SMS, Slack | 0 – 20 € |
| Grafana + PrometheusStack open source, maîtrise totale | Équipe DevOps | ✔ Via exporters | ✔ Via k6 ou Playwright | ~ Via plugin | ✔Complet | ✔AlertManager | 0 € (hébergement) |
| Site24x7Monitoring complet, bon rapport qualité-prix | ETI | ✔ Multi-localisations | ✔ Web journey | ✔Natif | ✔ API + serveur | ✔ Email, SMS, PagerDuty | 30 – 200 € |
| StatusCakeUptime + SSL + page speed | PME | ✔ 40+ localisations | ~ Basique | ✗ Non | ~ Limité | ~ Email, webhook | 0 – 40 € |
| Better UptimeUptime + pages de statut + on-call | ETI | ✔ Multi-localisations | ~ En développement | ✗ Non | ~ HTTP seul | ✔ On-call scheduling | 20 – 80 € |
Recommandation Eficiens pour les mutuelles et assureurs : la combinaison la plus efficace à coût maîtrisé est Pingdom (uptime + monitoring synthétique des parcours critiques + RUM) couplé à Datadog ou New Relic pour l’observabilité infrastructure et APIs chez les acteurs ayant une équipe DevOps. Pour les structures sans équipe technique dédiée, Site24x7 offre la couverture la plus complète dans un seul outil à prix raisonnable. UptimeRobot seul est insuffisant pour un site assurance — il ne détecte pas les pannes fonctionnelles.
Stratégie d’alertes et plan d’escalade
La détection d’un incident ne vaut rien sans une chaîne d’alerte claire qui garantit qu’une personne compétente est notifiée et peut agir, quelle que soit l’heure. C’est l’aspect le plus souvent négligé dans la configuration du monitoring.
Les canaux d’alerte disponibles
- Email : standard, mais inefficace la nuit et peu adapté aux incidents critiques qui nécessitent une réaction en moins de 10 minutes.
- SMS : fiable, rapide, fonctionne même en zone de mauvaise couverture data. À utiliser pour les alertes P1 (critiques).
- Appel vocal automatisé : proposé par PagerDuty, OpsGenie, Better Uptime. Réveille effectivement l’astreinte de nuit — la solution la plus efficace pour les incidents qui paralysent le parcours de souscription.
- Webhook Slack / Teams : excellent pour les alertes P2 et P3 pendant les heures ouvrées, intégré dans les workflows des équipes techniques.
- Intégration ITSM (ServiceNow, JIRA) : pour la création automatique de tickets d’incident et le suivi de la résolution, indispensable dans le cadre DORA.
Le plan d’escalade : qui prévient qui, quand
T+0 > Détection automatique — Alerte niveau 1
L’outil de monitoring détecte l’anomalie depuis au moins 2 points de présence différents (pour éliminer les faux positifs). Notification automatique à l’équipe technique d’astreinte par SMS et Slack.
T+5 min > Absence de prise en charge — Escalade niveau 2
Si aucune personne n’a acquitté l’alerte dans les 5 minutes, appel vocal automatique au responsable technique. Création automatique du ticket d’incident ITSM avec horodatage (requis pour la traçabilité DORA).
T+15 min > Incident critique confirmé — Escalade niveau 3
Si l’incident n’est pas résolu ou en cours de résolution, notification du DSI ou du directeur digital. Pour les incidents touchant le parcours de souscription ou l’espace client pendant les heures ouvrées : information de la relation client pour anticiper les appels entrants.
Résolution
Retour à la normale — Post-mortem
Notification de résolution sur tous les canaux. Déclenchement du post-mortem (analyse cause racine, chronologie, mesures correctives). Documentation dans le registre des incidents DORA si les seuils de criticité sont atteints.
Règle des deux points : ne jamais déclencher une alerte sur une seule détection. Les faux positifs (micro-coupure réseau d’un point de monitoring distant, timeout isolé) génèrent des alertes nocturnes abusives qui désensibilisent les équipes et conduisent à ignorer les vraies alertes. Configurez systématiquement la confirmation depuis au moins 2 localisations distinctes avant de déclencher la chaîne d’escalade.
DORA et le monitoring : vos obligations depuis janvier 2025
Le règlement DORA (Digital Operational Resilience Act) est entré en vigueur le 17 janvier 2025 pour l’ensemble des entités financières réglementées, dont les compagnies d’assurance, les mutuelles relevant du Code des assurances et les institutions de prévoyance soumises à Solvabilité II. Ses implications sur le monitoring sont concrètes et directement opérationnelles.
L’obligation de classification et de notification des incidents
DORA impose de classifier tous les incidents TIC selon leur niveau de criticité, selon des critères définis par les normes techniques de réglementation (RTS) publiées par l’EIOPA. Les incidents « majeurs » doivent être notifiés à l’ACPR (Autorité de Contrôle Prudentiel et de Résolution) dans les 24 heures suivant leur détection, avec un rapport initial, puis un rapport d’analyse dans les 72 heures.
Pour qu’une telle notification soit possible, votre système de monitoring doit être capable de fournir :
- L’horodatage précis du début de l’incident (première détection par le monitoring).
- La durée totale d’indisponibilité ou de dégradation.
- Les services et utilisateurs affectés.
- La chronologie des actions prises et des communications effectuées.
Sans monitoring automatisé avec logging horodaté, il est impossible de reconstituer cette chronologie avec la précision requise par les régulateurs.
L’exigence de tests de résilience
DORA impose également la réalisation de tests de résilience opérationnelle numérique à intervalles réguliers — dont des tests de basculement PRA. Ces tests doivent être documentés et leurs résultats intégrés au registre de résilience. Le monitoring est l’outil qui mesure le comportement du système pendant et après ces tests.
Point de vigilance réglementaire : les courtiers et intermédiaires d’assurance (soumis à DORA via leur dépendance aux systèmes des assureurs) sont également concernés si leur activité de distribution repose sur des systèmes informatiques. La frontière entre « entité réglementée » et « prestataire TIC » est au cœur des débats interprétatifs actuels avec l’ACPR. En cas de doute, consultez votre juriste ou votre compliance officer. Lire notre article sur l’impact de DORA sur les sites web assurance.
PRA et PCA : se préparer à l’inévitable
Aucun système n’est infaillible. Un Plan de Reprise d’Activité (PRA) et un Plan de Continuité d’Activité (PCA) ne sont pas des documents à produire une fois par an pour la compliance — ce sont des mécanismes opérationnels qui doivent s’enclencher automatiquement en cas d’incident, et être testés régulièrement.
Plan de Reprise d’Activité (PRA) — restaurer après incident
Le PRA définit les procédures techniques à activer pour restaurer le service après une interruption. Pour un site assurance, il doit couvrir :
- Basculement vers un environnement de secours : serveur secondaire ou CDN de backup activé automatiquement si le primaire devient indisponible. Le monitoring déclenche ce basculement sans intervention humaine si l’équipe est indisponible.
- Restauration depuis sauvegarde : en cas d’incident de données (corruption, intrusion), les sauvegardes doivent être disponibles et testées. Définir le RPO (Recovery Point Objective) — durée maximale de perte de données acceptable — et le RTO (Recovery Time Objective) — durée maximale de restauration acceptable.
- Page de maintenance : si une restauration prend du temps, afficher une page de statut informative avec un délai estimé plutôt qu’un écran d’erreur brut. Certains éditeurs (Better Uptime, Atlassian Statuspage) proposent des pages de statut publiques intégrées au monitoring.
Plan de Continuité d’Activité (PCA) — maintenir les services essentiels
Le PCA assure la continuité des services critiques pendant un incident. Pour un assureur, cela implique de définir quels services restent accessibles si le site principal est hors ligne : redirection des flux téléphoniques, activation du centre d’appel étendu, communication proactive aux adhérents via email ou SMS, accès aux documents contractuels via un portail de secours minimal.
Objectifs DORA pour le RTO/RPO : DORA n’impose pas de valeurs absolues pour le RTO et le RPO, mais exige qu’ils soient définis, documentés, testés et proportionnels à la criticité des services. Pour un parcours de souscription en ligne, un RTO de 4 heures est généralement considéré comme acceptable par les superviseurs. Pour un espace client permettant la déclaration de sinistre, un RTO de 2 heures est préférable.
Budget et mise en place : ce qu’il faut prévoir
Un dispositif de monitoring complet pour un site assurance (uptime + monitoring synthétique + RUM + infrastructure + alertes) se structure en trois niveaux de maturité :
- Niveau de base — Uptime + SSL + alertes email/SMS : UptimeRobot Pro ou StatusCake Pro, environ 15 à 40 €/mois. Suffisant pour un site vitrine sans parcours de souscription transactionnel. Insuffisant pour un site avec espace client ou tunnel de souscription.
- Niveau intermédiaire — Uptime + synthétique + RUM + infra : Pingdom Advanced ou Site24x7 Business, 80 à 250 €/mois selon le nombre de moniteurs et de points de vérification. Couvre l’essentiel des besoins d’une mutuelle ETI.
- Niveau avancé — Observabilité complète + DORA-ready : Datadog ou New Relic avec APM, synthetic monitoring, log management et dashboards de conformité DORA. 300 à 2 000 €/mois selon les volumes. Recommandé pour les groupes d’assurance avec des parcours transactionnels complexes et des obligations réglementaires fortes.
À ces coûts d’outillage s’ajoute le coût de mise en place et de configuration : comptez entre 3 000 et 15 000 € pour la configuration initiale (définition des moniteurs, écriture des scripts synthétiques, configuration des alertes et de l’escalade, intégration ITSM), selon la complexité des parcours à surveiller et le niveau de personnalisation des dashboards.
Pour aller plus loin sur les services d’infogérance et d’hébergement qui intègrent le monitoring, consultez notre page Infogérance et hébergement pour sites assurance.
Questions fréquentes sur le monitoring des sites web assurance
Quelle différence entre monitoring uptime et monitoring synthétique pour un site assurance ?
Le monitoring uptime vérifie qu’une URL donnée répond avec le bon code HTTP (200 OK). Il détecte les pannes totales du serveur, mais pas les pannes fonctionnelles : un formulaire de devis peut retourner 200 OK tout en étant cassé (erreur JavaScript, timeout de l’API tarificateur, champ obligatoire non fonctionnel).
Le monitoring synthétique exécute des scripts qui simulent le comportement d’un vrai utilisateur : cliquer sur « Obtenir un devis », remplir les champs, valider et vérifier que l’étape suivante s’affiche correctement. Il détecte les régressions fonctionnelles que l’uptime seul ne voit jamais. Pour un site assurance avec un parcours de souscription transactionnel, le monitoring synthétique est indispensable et doit couvrir chaque étape critique du tunnel.
DORA oblige-t-il les assureurs à mettre en place un système de monitoring ?
DORA n’impose pas explicitement d’utiliser tel ou tel outil de monitoring, mais il impose des obligations qui ne peuvent être satisfaites sans un monitoring automatisé : classification et notification des incidents TIC dans des délais précis (rapport initial à l’ACPR sous 24h pour un incident majeur), documentation horodatée de la chronologie de chaque incident, et tests de résilience réguliers documentés.
Sans monitoring automatisé, il est impossible de détecter un incident à l’heure exacte de son apparition, de reconstituer sa chronologie avec la précision requise, et de prouver aux superviseurs que les objectifs RTO/RPO ont été respectés. Le monitoring est donc un prérequis opérationnel à la conformité DORA, même s’il n’est pas nommément exigé dans le texte réglementaire.
Quel taux de disponibilité viser pour un site assurance et son espace client ?
Le minimum acceptable pour le site public d’un assureur est de 99,9 % (soit moins de 8,7 heures d’interruption par an). Pour l’espace client — qui donne accès aux contrats, aux attestations et à la déclaration de sinistres — le seuil recommandé est 99,95 % (moins de 4,4 heures par an).
Ces taux doivent être contractualisés avec votre hébergeur sous forme de SLA avec pénalités en cas de dépassement. Il est également important de distinguer la disponibilité 24h/24 de la disponibilité aux heures ouvrées : certains hébergeurs calculent leur SLA sur des fenêtres horaires qui excluent les nuits et week-ends — ce qui est inacceptable pour un espace client accessible à toute heure.
Quels sont les outils de monitoring les plus adaptés à un assureur ou une mutuelle ?
Le choix dépend de la taille de la structure et de la maturité de l’équipe technique. Pour une mutuelle ETI sans équipe DevOps dédiée, Pingdom ou Site24x7 offrent le meilleur équilibre entre complétude fonctionnelle (uptime, monitoring synthétique, RUM) et facilité de configuration, pour 80 à 250 €/mois.
Pour un groupe d’assurance avec une équipe DevOps et des obligations DORA fortes, Datadog ou New Relic offrent l’observabilité complète nécessaire : APM, log management, dashboards de conformité, intégration ITSM. L’investissement est plus élevé (300 à 2 000 €/mois) mais la couverture est sans équivalent. UptimeRobot seul est insuffisant pour tout site assurance avec un parcours transactionnel.
Combien coûte la mise en place d'un dispositif de monitoring complet pour un site assurance ?
Le budget se décompose en deux postes : l’abonnement aux outils (15 à 2 000 €/mois selon le niveau de couverture) et la configuration initiale (3 000 à 15 000 € en prestation selon la complexité des parcours à instrumenter et le niveau de personnalisation des alertes).
Pour une mutuelle intermédiaire avec un site public et un espace client, comptez un budget annuel de 2 000 à 5 000 € pour l’outillage et une configuration initiale de 5 000 à 10 000 €. Ce coût est sans commune mesure avec le coût d’une interruption non détectée pendant 4 heures sur un parcours de souscription en pleine campagne de renouvellement.
Comment tester l'efficacité de son plan de reprise d'activité (PRA) ?
Un PRA qui n’a jamais été testé ne vaut rien. Les tests doivent être réalisés au minimum une fois par an, et idéalement deux fois — une fois planifiée et documentée, une fois en conditions semi-réelles (notification à l’équipe le matin même, sans préparation préalable).
Le test consiste à simuler la panne du serveur principal (en le coupant ou en simulant une indisponibilité dans l’environnement de monitoring), à déclencher le basculement PRA, et à mesurer le RTO réel (temps écoulé entre la détection et la restauration complète du service). Le résultat est documenté et comparé au RTO contractuel avec l’hébergeur. DORA exige que ces tests et leurs résultats soient archivés et accessibles aux superviseurs sur demande.
Votre dispositif de monitoring est-il à la hauteur des enjeux DORA ?
Tous les détails sur notre page contact ou en visio ci-dessous





